Following is a representative list of publications, book chapters and articles that I’ve co-authored in data and analytics space. For a comprehensive listing with citations, see Google Scholar .
I also have 100+ pending/granted patents, some of which are listed here.
1. Principled Reference Data Management for Big Data and Business Intelligence
 Most large enterprises requiring operational business processes utilize several thousand instances of legacy, upgraded, cloud-based, and/or acquired information management applications. With the advent of Big Data, Business Intelligence (BI) systems, receive unconsolidated data from a wide-range of data sources with no overarching governance procedures to ensure quality and consistency. Although different applications deal with their own flavor of data, reference data is found in all of them.
Most large enterprises requiring operational business processes utilize several thousand instances of legacy, upgraded, cloud-based, and/or acquired information management applications. With the advent of Big Data, Business Intelligence (BI) systems, receive unconsolidated data from a wide-range of data sources with no overarching governance procedures to ensure quality and consistency. Although different applications deal with their own flavor of data, reference data is found in all of them.
Given the critical role that BI plays in ensuring business success, the fact that BI relies heavily on the quality of data to ensure that the intelligence being provided is trustworthy, and the prevalence of reference data in the information integration landscape, a principled approach towards management, stewardship and governance of reference data becomes necessary to ensure quality and operational excellence across BI systems.
The authors discuss this approach in context of typical reference data management concepts and features, leading to a comprehensive solution architecture for BI integration.
2. Technical Strategies for Information Virtualization
Over the years, the information landscape within many organizations has become increasingly complex. More information is used by 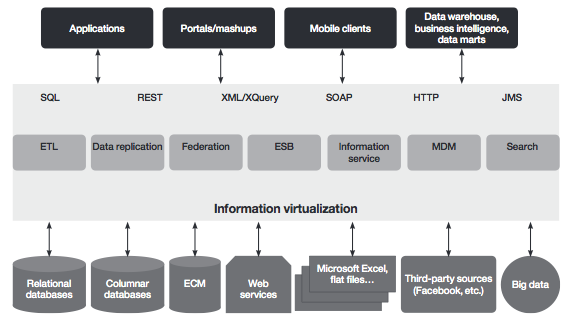 more applications that are reaching more people. Mergers, acquisitions and global expansion meld disparate systems within enterprises and expand them regionally. Throughout the world, new business models have been built around easy access to and sharing of information.
more applications that are reaching more people. Mergers, acquisitions and global expansion meld disparate systems within enterprises and expand them regionally. Throughout the world, new business models have been built around easy access to and sharing of information.
Greater data accessibility provides new opportunities, but much of the data within organizations is accessible only to those who know where the information is, how to get it and how to use it. The growing value of underutilized information has led to a range of architectural strategies, technologies and patterns to harness their potential.
 Collectively, this set of capabilities can be called information virtualization (IV). IBM uses this term instead of data virtualization because IV encompasses not only the traditional structured data, but all varieties of data—an important distinction since data with less structure has become more commonplace with the rise of big data.
Collectively, this set of capabilities can be called information virtualization (IV). IBM uses this term instead of data virtualization because IV encompasses not only the traditional structured data, but all varieties of data—an important distinction since data with less structure has become more commonplace with the rise of big data.
This paper discusses key IV technologies and offers several ways to form technical strategies for specific situations. It focuses on a pragmatic approach to evaluating business constraints, requirements and the technical environment in developing an architecture to meet current and planned information needs.
3. Ontology-guided Extraction of Complex Nested Relationships
Many applications call for methods to enable automatic extraction of structured information from unstructured natural language text.  Due to inherent challenges of natural language processing, most of the existing methods for information extraction from text tend to be domain specific. We explore a modular ontology-based approach to information extraction that decouples domain-specific knowledge from the rules used for information extraction. We describe a framework for extraction of a subset of complex nested relationships (e.g., Joe reports that Jim is a reliable employee). The extracted relationships are output in the form of sets of RDF (resource description framework) triples, which can be queried using query languages for RDF and mined for knowledge acquisition.
Due to inherent challenges of natural language processing, most of the existing methods for information extraction from text tend to be domain specific. We explore a modular ontology-based approach to information extraction that decouples domain-specific knowledge from the rules used for information extraction. We describe a framework for extraction of a subset of complex nested relationships (e.g., Joe reports that Jim is a reliable employee). The extracted relationships are output in the form of sets of RDF (resource description framework) triples, which can be queried using query languages for RDF and mined for knowledge acquisition.
4. Metadata Exploitation in Large-scale Data Migration Projects
The inherent complexity of large-scale information integration efforts has led to the proliferation of numerous metadata capabilities to improve upon project management, quality control and governance.
improve upon project management, quality control and governance.
In this paper, we utilise complex information integration projects in the context of SAP application consolidation to analyse several new metadata capabilities, which enable improved governance and control of data quality.
Further, by investigating certain unaddressed aspects around these capabilities, often tending to negatively impact information integration projects, we identify key focus areas for shaping future industrial and academic research efforts.
5. Practical Guide to Managing Reference Data with IBM InfoSphere Reference Data Management Hub

IBM InfoSphere Master Data Management Reference Data Management Hub (InfoSphere MDM Ref DM Hub) is designed as a ready-to-run application that provides the governance, process, security, and audit control for managing reference data as an enterprise standard, resulting in fewer errors, reduced business risk and cost savings.
This IBM Redbooks publication describes where InfoSphere MDM Ref DM Hub fits into information management reference architecture. It explains the end-to-end process of an InfoSphere MDM Ref DM Hub implementation including the considerations of planning a reference data management project, requirements gathering and analysis, model design in detail, and integration considerations and scenarios. It then shows implementation examples and the ongoing administration tasks.
This publication can help IT professionals who are interested or have a need to manage reference data efficiently and implement an InfoSphere MDM Ref DM Hub solution with ease.
6. Ontology-guided Reference Data Alignment in Information Integration Projects
One of the hard problems in information integration projects (harmonizing data from various legacy sources into one or more targets) is the appropriate alignment of reference data values across systems.
Without this 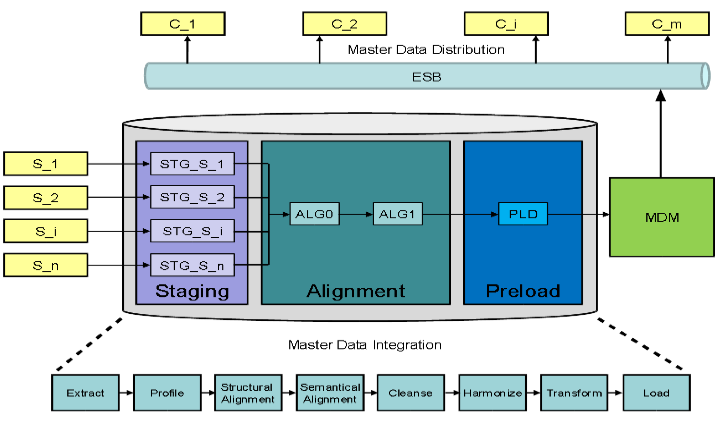 alignment, the process of loading records into the target systems might fail because the target might reject any record with an unknown reference data value or different underlying data semantics.
alignment, the process of loading records into the target systems might fail because the target might reject any record with an unknown reference data value or different underlying data semantics.
Today, detecting reference data tables and determining the relative alignment between a source and a target is largely manual, cumbersome, error-prone and costly.
We propose a semantic approach to detect reference data tables and their relative alignment across source/target systems to enable semi-automated creation of translation tables.